SDMuse: Stochastic Differential Music Editing and Generation via Hybrid Representation
While deep generative models have empowered music generation, it remains a challenging and under-explored problem to edit an existing musical piece at fine granularity. In this paper, we propose SDMuse, a unified stochastic differential music editing and generation framework, which can not only compose a whole musical piece from scratch, but also modify existing musical pieces in many ways, such as combination, continuation, inpainting, and style transferring. SDMuse is based on a diffusion model generative prior, synthesizing a musical piece by iteratively denoising through a stochastic differential equation.
Considering the pianoroll and MIDI-event are suitable for editing and modeling respectively, we design a two-stage pipeline, including pianoroll and MIDI-event generation, which takes advantage of two kinds of symbolic music representations (we call it hybrid representation).
We evaluate the generated music of our method on ailabs1k7 pop music dataset in terms of quality and controllability on various music editing and generation tasks. Experimental results demonstrate the effectiveness of our proposed stochastic differential music editing and generation process, as well as the hybrid representations.
Generation from Scratch
REMI
CPW
SDMuse (unconditioned)
SDMuse (conditioned)
Fine-grained Editing
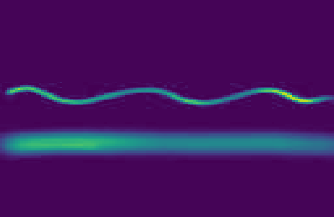
Stroke-based Generation
Input Audio
Input
Mask
Pianoroll
Audio
None
None
None
None
None
None
Stroke-based Editing
Input Audio
Input
Mask
Pianoroll
Audio
None
None
None
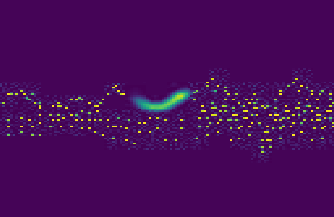
Inpainting
The mask starts at about the 24 second of the original audio input.